2025年的盛夏,当全球科技圈仍在为GPT-5的传闻争论不休时,一份来自Artificial Analysis的《2025年第一季度全球大模型应用趋势报告》悄然揭开了行业真实面貌。这份覆盖欧美亚千余家企业(涵盖科技巨头、传统制造、政府机构及教育系统)的调研,不仅用数据勾勒出大模型从”实验室玩具”到”生产刚需”的跃迁轨迹,更暴露出红海竞争下的生态暗战与落地痛点。
一、生产落地:45%企业的”关键一跃”,工程研发成主战场
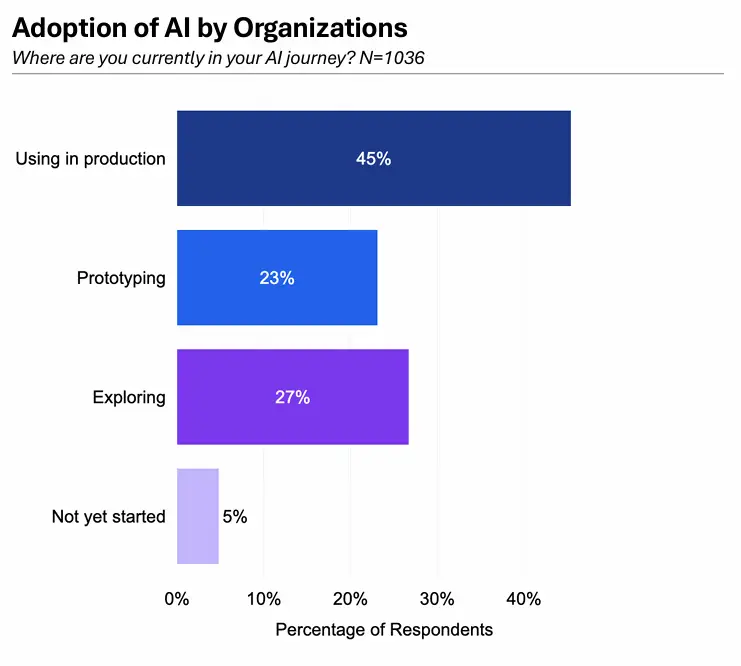
“大模型不再是技术部门的‘炫技工具’,而是开始真正走进生产线。”报告开篇的结论,印证了AI产业的关键转折。数据显示,45%的企业已将大模型部署至生产环境,较2024年同期提升18个百分点——这意味着大模型正从”概念验证”阶段加速向”价值创造”阶段跃迁。
从应用场景看,工程研发(66%企业计划重点投入)、客户支持(37%)与营销(33%)构成了当前最活跃的”智能三角”。某汽车制造企业的AI负责人在访谈中透露:”我们用大模型优化了供应链预测模型,将零部件库存周转周期缩短了22%,仅这一项每年节省成本超千万。”而在客户服务领域,某跨国电商的实践更具代表性:其基于大模型的多语言智能客服,不仅将用户问题解决率从78%提升至89%,更通过情感分析功能识别用户情绪波动,主动转接人工客服,投诉率下降15%。
不过,生产落地的广度仍存局限。23%的企业仍将大模型用于原型构建,27%主要用于搜索信息——这表明,尽管部分场景已跑通商业模式,但多数企业对大模型的定位仍偏向”效率工具”,而非”核心生产要素”。正如报告分析:”可解释性与鲁棒性的不足,让企业在关键决策环节仍持谨慎态度。”
二、付费模式分化:从”白嫖测试”到”定制深耕”,企业需求分层明显
面对大模型的”工具属性”,企业的付费策略正呈现鲜明的分层特征。32%的企业选择”定制化开发”,27%依赖API调用标准服务,25%采取”双轨模式”(既自研又用第三方服务),仅16%的受访者承认仍在”白嫖”(使用免费试用版或开源模型)。这种差异背后,是企业规模与需求的深度绑定。
大型科技公司与行业龙头更倾向定制化路径。某金融集团AI实验室负责人坦言:”我们的风控场景需要处理大量非结构化数据,通用模型难以满足合规要求,必须基于自有数据微调模型。”而中小企业则更依赖API服务——某跨境电商初创公司CTO表示:”我们没有技术团队,通过调用大模型API快速搭建了智能选品系统,初期投入仅传统方案的1/5。”
值得注意的是,”双轨模式”正成为中大型企业的”折中选择”。某制造业龙头CIO解释:”自研模型用于核心业务(如工艺优化),API服务用于边缘场景(如员工培训),既能保证关键数据安全,又能降低非核心业务的试错成本。”
三、挑战与破局:可靠性、成本、智能水平成”三座大山”
尽管应用加速,但大模型的落地之路依然布满荆棘。报告调研显示,当前企业面临的核心挑战中,”知识水平不足”(55%)高居榜首——模型常因训练数据时效性差或专业领域覆盖不全,导致生成内容错误;”人工智障时刻”(50%)紧随其后,典型表现是逻辑混乱、答非所问;”高昂成本”(50%)则让中小企业望而却步,某SaaS企业技术总监透露:”我们每月大模型调用费用占研发预算的35%,若能降低至20%,就能将服务范围扩大一倍。”
此外,”系统整合难度”(42%)、”响应速度”(38%)与”监管合规”(31%)也成为隐性门槛。某工业软件公司的技术负责人举例:”我们需要将大模型嵌入现有的ERP系统,但接口协议不兼容,光是调试就花了3个月。”而在医疗、金融等强监管行业,数据隐私与输出内容的可追溯性要求,更让企业不得不额外投入合规成本。
四、市场格局:4.7个模型”混搭”成常态,OpenAI守擂,国产模型”谨慎突围”
在”用什么模型”的选择上,全球企业正上演一场”多情大戏”。报告显示,受访者平均同时使用4.7家不同的大模型,品牌忠诚度几乎为零——这既是红海竞争的缩影,也反映出企业”货比三家”的务实心态。
从竞争态势看,OpenAI凭借先发优势与生态壁垒稳居头把交椅,其模型在编程助手、创意生成等场景的用户粘性仍领先;谷歌Gemini则凭借多模态能力(尤其是视频生成)强势崛起,用户增速居首;Claude与Llama略显疲态,部分用户反馈其在复杂任务处理上”后劲不足”。值得关注的是,新玩家正加速入场:xAI的Grok以”实时信息整合”为卖点,在北美年轻用户中快速渗透;阿里Qwen则依托跨境电商场景,在东南亚市场获得12%的用户覆盖率。
国产模型的出海之路则呈现”谨慎接纳”的特征。55%的受访者表示愿意使用中国大模型,但明确要求”部署在中国之外的基础设施”——这一比例在欧美市场高达68%。某出海科技企业的技术负责人透露:”我们曾尝试直接部署国内模型,但因数据跨境合规问题被客户叫停;后来通过第三方服务商(如Manus)在新加坡搭建算力中心,才打开市场。”这一现象提示,国产大模型的全球化需突破”基础设施信任”与”数据安全合规”双重壁垒。
五、硬件与多模态:英伟达”生态霸权”延续,视频生成仍待突破
大模型的竞争,本质是算力与生态的竞争。在训练硬件领域,英伟达以78%的份额延续”绝对统治”,其CUDA生态的不可替代性仍是最大护城河;谷歌TPU(12%)与AMD(8%)虽分列二三位,但主要服务于自有云服务,难以撼动英伟达的第三方合作网络。
多模态应用的分化则更值得玩味:在语言生成场景,OpenAI仍主导市场,但优势并不碾压;语音生成领域,用户最关注”真实性”与”延迟”,某智能硬件厂商的测试显示,头部模型的中文语音拟真度已达92%,但复杂对话场景下的响应延迟仍普遍在800ms以上;视频生成赛道的竞争更趋激烈,尽管OpenAI仍是最常用模型,但用户对其”提示词遵循度”的不满率达47%——”输入‘夕阳下的海边少女’,输出的却是阴天场景”成为高频吐槽。
智能时代的”生态重构战”才刚刚开始
2025年的大模型应用图景,既展现了技术落地的加速度,也暴露了产业成熟的阵痛。当45%的企业将大模型视为生产刚需,当用户平均使用4.7个模型”用脚投票”,当英伟达以78%的份额稳坐硬件王座——这些数据共同指向一个结论:大模型已从”技术竞赛”进入”生态战争”阶段。
未来的胜负手,或许藏在三个关键变量中:其一,模型能否突破”知识时效性”与”专业深度”的限制,真正成为各行业的”智能大脑”;其二,企业能否通过定制化与标准化结合的付费模式,降低中小用户的接入门槛;其三,全球产业链能否在”数据安全”与”技术合作”间找到平衡,让中国模型等新兴力量真正融入全球生态。
正如报告在总结中所言:”大模型的黄金时代,不在实验室的论文里,而在工厂的产线中、客服的对话框里、设计师的电脑屏幕上。”当技术真正扎根于需求,智能时代的生态重构,才刚刚开始。
发表回复